Voxel vs Point Based Approaches in 3D Deep Learning: Who wins a fight?
A few weeks ago, I was celebrating my birthday with friends, when I plugged my TV to see the results of the "European Elections". And then... Lightning Strike! ⚡️ French President Emmanuel Macron, after losing against the extreme parties, decided to dissolve the Assembly.
In other words, every French citizen is invited to "re"vote, but this time for our own government. A lot of people called it a "poker move", others said it put the country in chaos, and a few were eager to vote and replace Macron with whoever they preferred.
France has reached a "US-level" division, with half of the country going far left, and the other half going "far right". Something unseen before. What's interesting is, they all think they have the right solution to fix France.
We now more than ever have an opposition between two ideas, two solutions to solve a problem...
We've seen this with Apple vs Microsoft before; one wanting utmost control of hardware and software; while the other wants a versatile OS working on every possible platform. We've seen it with Musk and Besoz, each having its own solution to win the space race. Or with Intel vs AMD. We've seen it in war tactics, in market disruption strategies, in investment...
... and now... we're seeing a division of two approaches in 3D Deep Learning.
In the 3D Deep Learning world, the fight happens between Voxels and Points. And you'll see how similarly, one approach is conservative, versatile, "safe", and the other is more innovative, disruptive, and precise.
What we're trying to understand is much simpler than french politics — how on earth can we classify a point cloud using Neural Networks?

Let's take a look...
Point Based Approaches: From PointNet to Point Transformers
Coming from the Computer Vision world, what do you have at disposal to use Deep Learning on Point Clouds? Not so much, but mainly, the Multi-Layer Perceptron, and the 2D Convolution.
Yes, but a point cloud is infinitely harder to process than an image. An image has a fixed width and height, it's a rectangular matrix where every pixel lies between 0 and 255, nearby pixels belong to the same object, and it's all flat 2D.
On the other hand, point clouds are chaotic. There is no order, no color, and no continuity between the points. The structure is 3D, it can rotate or change scale, and points aren't evenly spaced. Any random shuffling or data augmentation could destroy a convolution's output. In other word, it's chaos.
You cannot apply traditional CNNs on Point Clouds, and this is why the PointNet architecture has been invented. At the time, rather than a 2D convolution, PointNet used shared MLPs (implemented via 1x1 convolutions) to learn features from a point cloud. It also used Spatial Transformer Networks and Max Pooling to classify or segment a point cloud.
The architecture from 2016 looks like this:
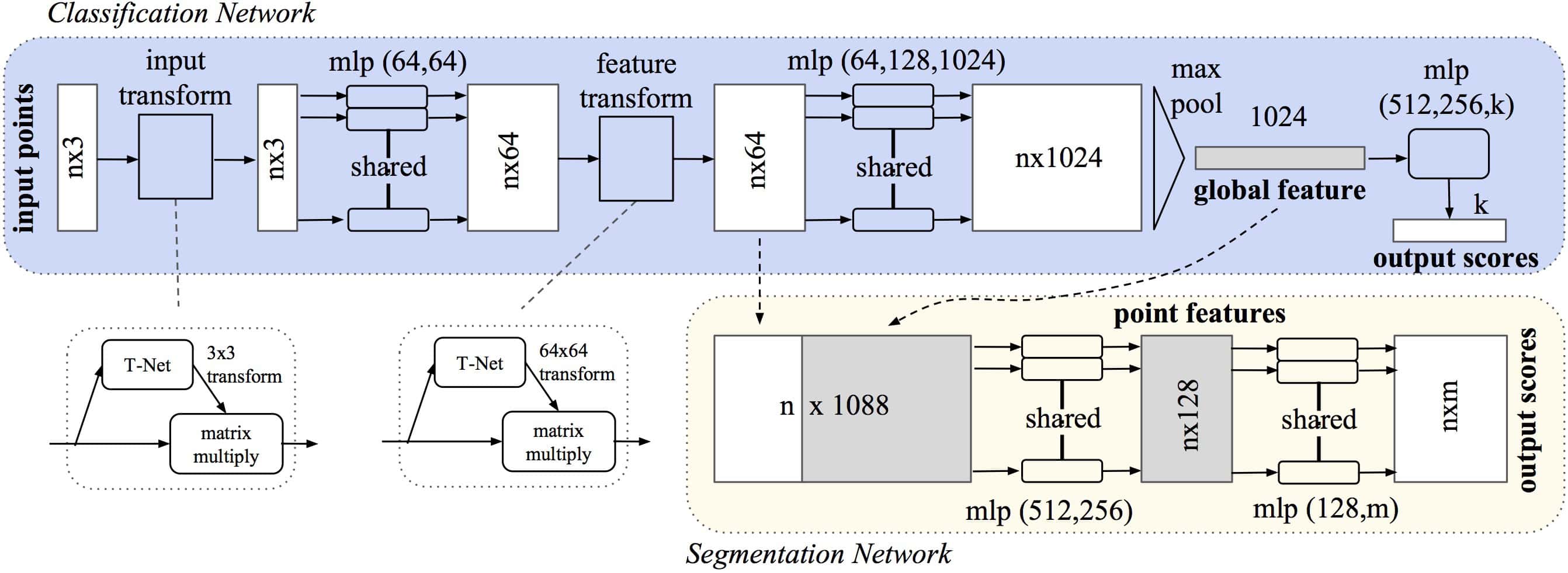
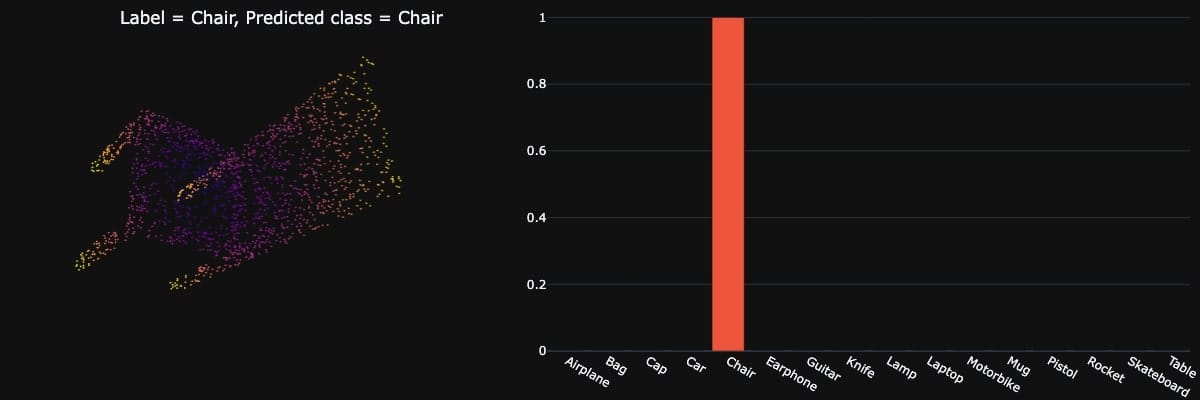
PointNet can classify a point cloud, segment it, and even segment its subparts. Like this:
So, this is the "VGG" equivalent. If I had to draw a parallel:
- In an image approach, VGG/ResNet is used to extract features, and the rest of the architecture is about doing the task (object detection, segmentation, ...)
- In a point cloud approach, PointNet/PointNet++ is used to extract features, and the rest of the architecture does the tasks.
Since PointNet (2016) and PointNet++ (2017), many other extractors and architectures followed, such as PointCNN (2018), DGCNN (2019), PointNeXt (2022), Point-MLP (2022), or even — what's today considered as state-of-the-art, Point Transformers v3 (2023/2024). You can find many of them explained in my Deep Point Clouds course.
⚠️ Now, a note: These are feature extractors. Their purpose is simply to learn features from point clouds directly, you're never going to do 3D Object Detection or 3D Tracking with it. But you can include them in 3D Object Detectors.
Let's see how...
Fitting PointNet inside a 3D Architecture
Let's take for example, Point-RCNN (2019). This is a two-stage 3D Deep Learning algorithm that uses PointNet++ and a well-crafted structure to implement 3D Object Detection:

This is what we're looking for. It's using PointNet, but it's not PointNet, it's an extension of it.
When looking at the architecture, it resembles this:
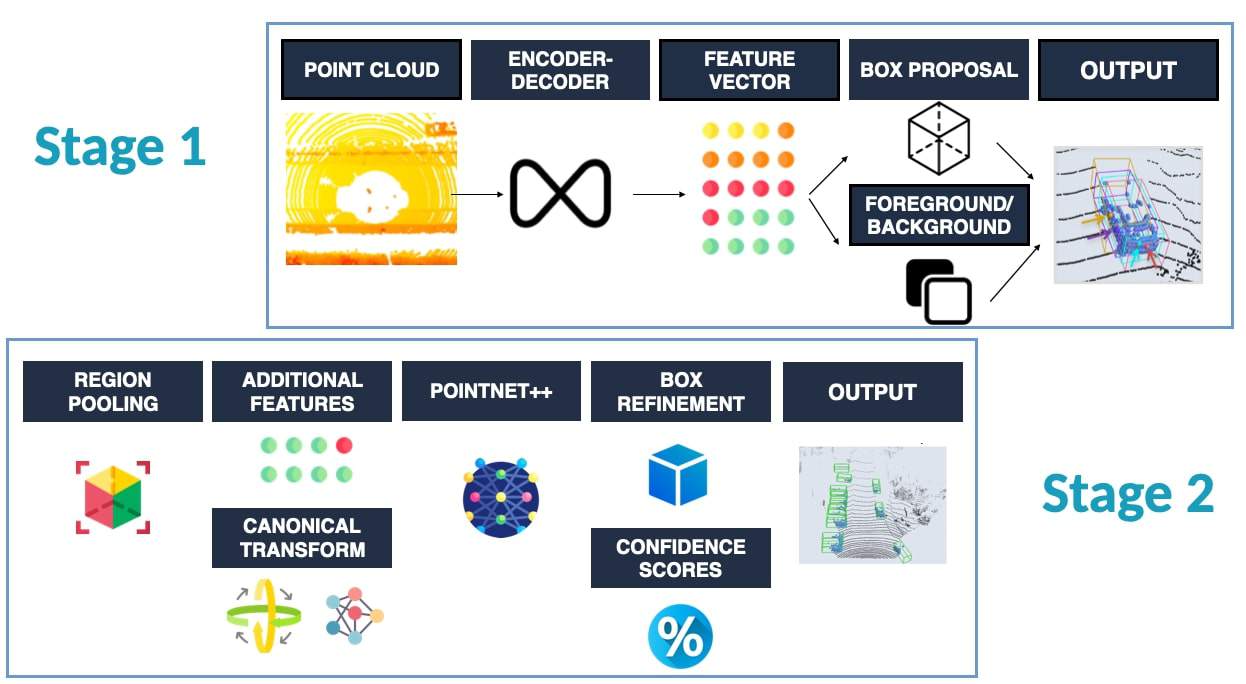
And when you look at it, you begin from a point cloud, then learn features for each point, and then end up adding algorithms, like foreground/background detection, bounding box regression, and others to get to your objective...
Similarly, many approaches exists , and they all use an extractor. CenterPoint (2021) uses PointNet++ and then generates centers of object locations. H3DNet (2020) uses PointNet++ as well. And so on...
Okay, so this is one approach, what is the other?
Voxel Based Approaches
The second idea is not a direct approach; because it involves "voxels". If you've ever heard names like "VoxelNet", or "PointPillars", this is that. So what is a voxel? And why is this the #2 technique?
Let's go back to our idea of 2D Convolution not working on Point Clouds. We saw the point cloud is naturally unstructured, the number of point changes at every frame, and so on... But there is a way to solve this, other than inventing a PointNet... voxelization.
Pixel vs Voxel
To give an analogy, a voxel is a 3D pixel. When we have a point cloud, we have 3D shapes that can't work with our 2D Convolutions; but when converting this point cloud to a set of "voxels", we can then use, not 2D, but 3D Convolutions.
So for example, we could split the space (yes, the "air") into 50*50*50 cm grids, and consider these as voxels. You then take the average of the points inside and give it a value. If no point is inside, you consider it empty.
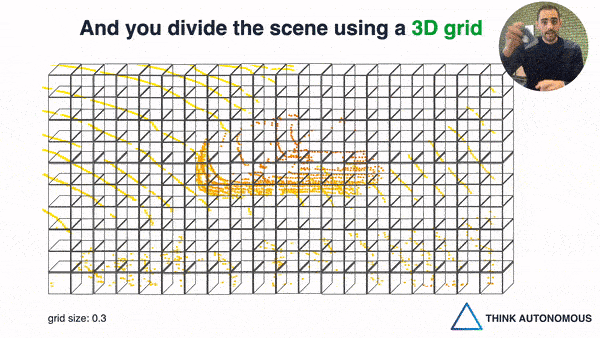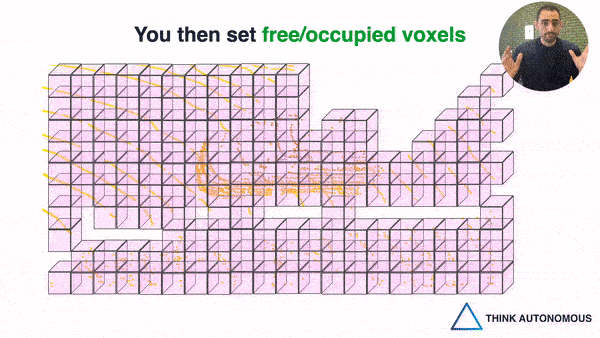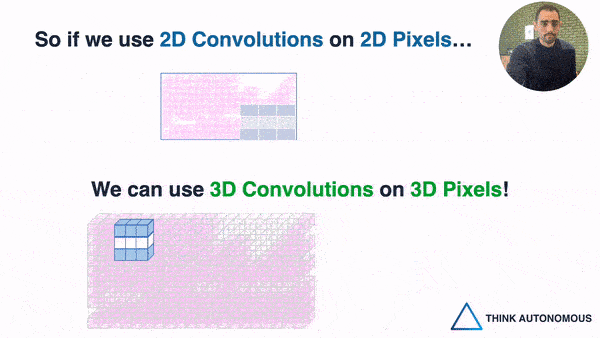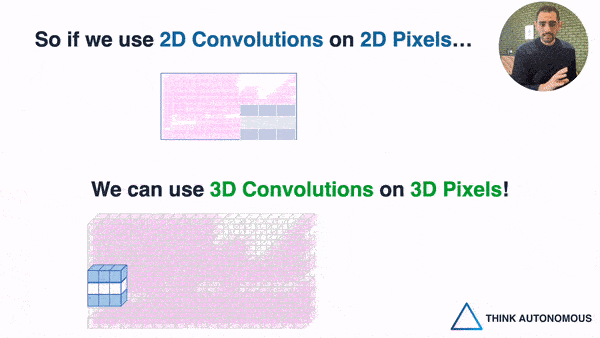
So , this is the second way, and it's great, because when the space is voxelized, you CAN use 3D Convolutions. You can even implement 3D Convolutional Neural Networks, and basically replicate everything you know about image convolutions to point clouds.
The "end" could look like this:
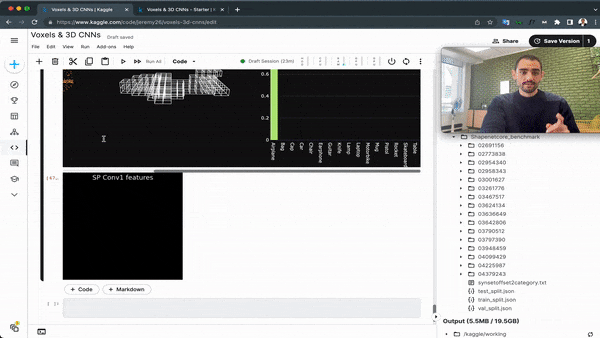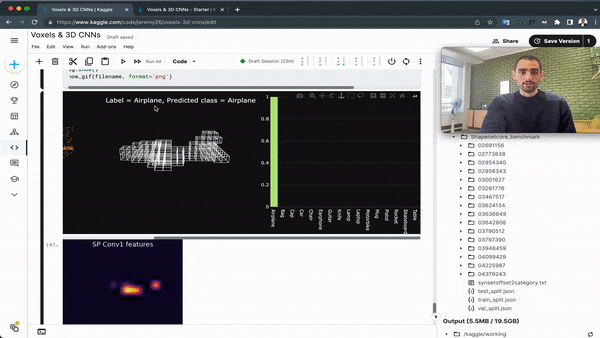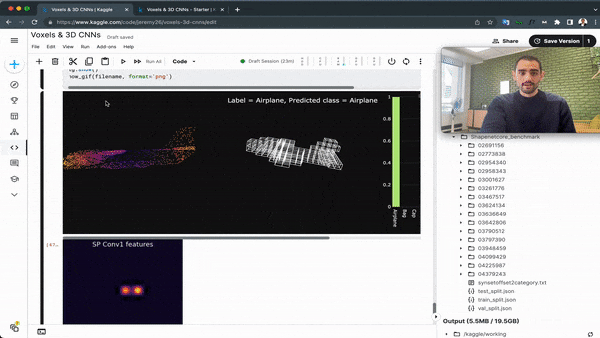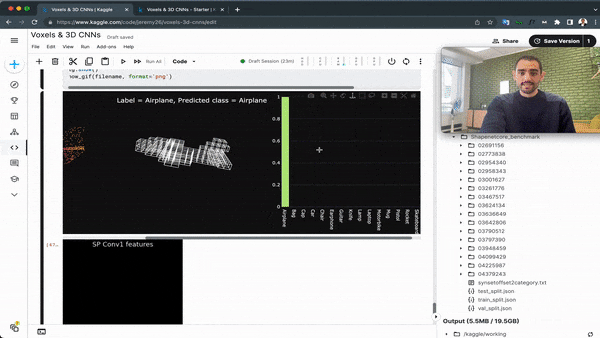
This idea has been replicated in 2D, via an algorithm named "Point Pillar", and had many variations over the years. And just like a PointNet can fit into a Point-RCNN, a voxel network could fit into a Voxel-RCNN.
The output would look like this:

So you now get the two types of approaches:
- One uses "PointNets" to learn from points directly
- One uses a "Voxelization" process first, to learn using 3D Convolutions
But which one is better?
Comparing the two approaches 🥊
Let's first use our intuition...
Imagine you have a point cloud, and its voxelized version, like this:

Which of the two do you think provides more information? Intuitively, the point cloud hasn't been through a conversion process, it didn't have the "loss of information" we could have from voxelizing a scene — it's also more "precise" around the edges. So it's a big win for the point based approaches!
On the speed aspect, point based approaches don't have this extra voxelization process. They directly work with the raw points, and can even adapt, generate graphs, work with sparse data, and so on... Point based approaches really ARE the innovative solutions.
YES BUT:
Voxels use Convolutions. Are we know extremely well how to stack convolutions together, how to make them efficient, how to use pyramid architectures at multi-scales, how to visualize the features learned, and so, we have amazing well-known ways to create stunning architectures using Voxels. In other words, the "conservative" way is this one.
At first, researchers only knew how to use voxels. Then, in the 2016-2019 era, people shifted to point based approaches since PointNet came. In the meantime, interesting approaches like PointPillars got released on the voxel aspect. And now, we have state of the art approaches for both, and even for point-voxel based approaches!
Okay, let's see a few examples:
Example #1: Point-Transformer
The first example I want to pick is the v1 Point Transformer.

This architecture works on the points directly, and you can see 3 distinct blocks repeated:
- The Point Transformer Block, which implements self-attention and MLPs
- The Transition Down, which involves sampling points, finding the K-nearest neighbors, and doing a local max pooling
- The Sampling Up, which uses interpolation to upsample the point cloud (similarly to a UNet architecture)
Okay, so this is just for you to "see" the types of operations we can apply on point clouds...
Example #2: VoxelNet
This second example is much simpler to understand, but it's one of the "pillars" that shows extremely well everything going on in a Voxel based approach:
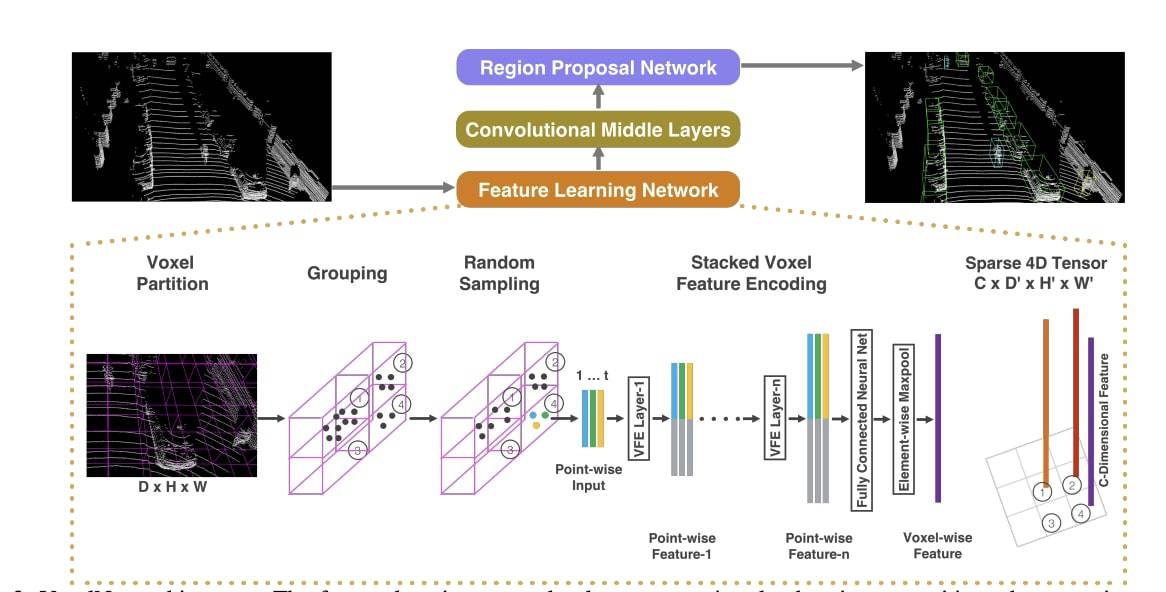
As you can see, it begins with a Feature Learning Network, that doesn't just involve "voxelization", but VFE (Voxel Feature Extraction), stacking voxels together, running fully convolutional networks, etc... and then, using 3D Convolutions in the middle layers before going with a Region Proposal Network for Bounding Box generation.
FYI — I'm doing a complete study of this algorithm in my course "DEEP POINT CLOUDS".
Aren't there other ways? What about Bird Eye View?
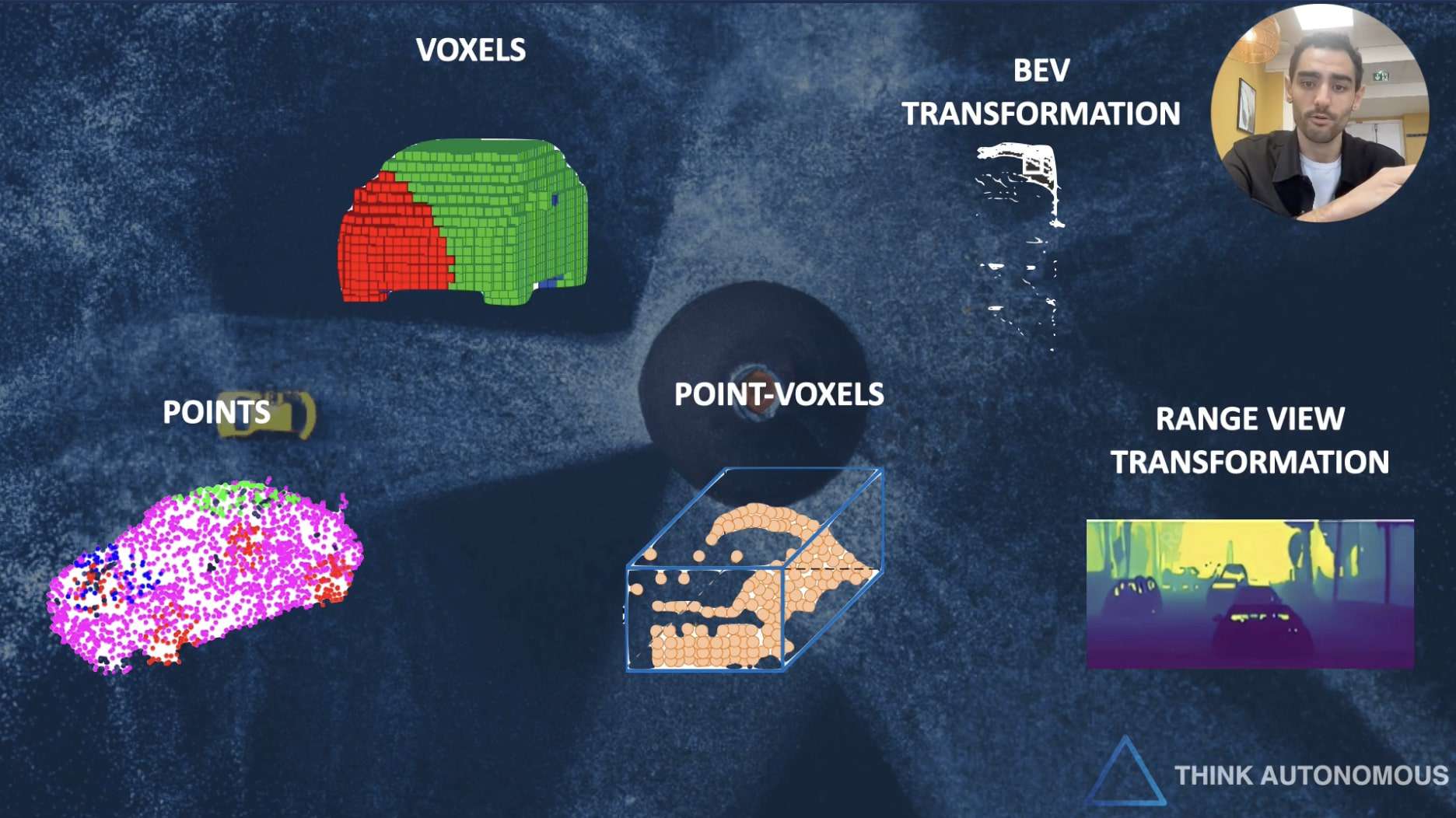
Yes, there are other ways! Point and Voxel based approaches are the 2 "main" ways to process point clouds with 3D Deep Learning, but I counted at least 3 more:
- Point-Voxel based approaches (Hybrid): This leverages the better of the two worlds, and can get very sophisticated. I'm doing a full study + implementation of one named PV-RCNN in the DLC of my Deep Point Clouds course.
- Bird Eye View approaches: If you don't want to convert to voxels, you can also convert to Bird Eye View. This is a bit like "cheating", but Bird Eye View allows you to remove one dimension and work in 2D. This is what the "Point Pillar" algorithm is doing.
- Range View approaches: If you don't want to use points, or voxels, or even Bird Eye View, you can use "Range View". A Range view is like a depth map. It's a 2D front image, but with depth values in it. So essentially, you can use normal image convolutions on it.
- Anything else? We could use Graph Neural Networks, but this would mean going back to the idea of processing points directly. We could use Occupancy Networks, but these really are voxels. So I think we're good!
Okay, we've seen a lot of things in this article, let's do a summary.
Summary
- If you want to use Deep Learning on Point Clouds, the normal 2D Convolutions won't work. Point clouds are randomly set, they don't obey to a structure, and convolution operations could break them.
- We have 2 main ways to process point clouds with Deep Learning: point based (direct processing) and voxel based (voxelization, then convolutions)
- Point based approaches began with PointNet, and implement the idea of processing the points directly, by learning features for every point and aggregating everything. Other approaches such as PointNet++, PointCNN, or Point Transformers followed.
- Voxel based approaches first convert a point cloud into a voxel grid, and then process the points, this time using 3D Convolutions. The voxelization creates order among chaos, and allows to use 3D Convolutions on point clouds.
- You can fit any point or voxel based extractor into an architecture, for example Point-RCNN, VoxelNet, PV-RCNN, and more...
- In most cases, you'll need to use additional operations, such as sampling the points, clustering them, detecting foreground/background, etc...
- There are other ways to process point clouds. For example, you could turn the point cloud into a Bird Eye View, or a Range View. The best way is currently, I think, the Point-Voxel approaches (hybrid).
Many times, when two ideas conflict eachother, there's a clash. I don't know how the french clash will end, but in the 3D Deep Learning world, we have a point based solution that seems more innovative, but struggled for a long time with available tools.... while the other approach uses well-known techniques, but seems limited by its very structure.
Next Steps
Congratulations on reaching the end of this (quite long) article! If you'd like to go further in the world of 3D Deep Learning, there are many things you can do, such as:
Studying the fundamentals — PointNet, PointNet++, Voxelization, etc... and even everything Machine Learning based (because; why going to 3D Deep Learning first?)
When signing up for the waitlist, you'll also get goodies talking more about 3D Deep Learning while you wait. It's here to learn more.