Video Segmentation: Why the shift from image to video processing is essential in Computer Vision
In 1897, French police faced a difficult problem: a serial killer named Joseph Vacher was stealing and murdering sheperds, and remained impossible to catch. Every time he was arrested, he gave a different name, changed his appearance, used fake mustaches, wigs, and different clothing styles... and got to disappear without the police realizing they just controlled France's most wanted man.
At the time, France had no national ID system, and no way to prove that the man they caught today was the same man they arrested months ago. That was until an officer named Alphonse Bertillon introduced a revolutionary method: anthropometry. It's a system that labeled criminals based on of 12 unchangeable physical measurements like ear shapes, skull sizes, and limb lengths, that could not be faked.
One day, Vacher was caught for attacking a woman, and this time, the police used Bertillon's system to compare his measurements to what they had in their records: they discovered they just caught France's most wanted criminal. This time, he could not escape with a warning, and got sent to... yeah — the guillotine 🤷🏻♂️🇫🇷
What got Vacher executed wasn’t just this one-time capture, but the ability to analyze a series of events and not just a one-time event. And this is exactly what this article is about: the shift from frame-by-frame to sequence processing, here in Computer Vision with videos. And this is done via something called video segmentation.
So let's get started:
What is Video Segmentation?
Most Computer Vision Engineers spend time learning about image processing, but never consider what happens when you use a video. Yet, tons of architectures today, whether in surveillance, retail, sports analysis, healthcare, or even robotics and self-driving cars — now process videos instead of images. The sequence brings something individual images don't, just like the Vacher story, where he was able to get judged through all the murders he committed.
So let's take a less deadly scene — shoplifting detection in retail. There is a startup I once interviewed for named Veesion — that has this amazing video on their homepage:
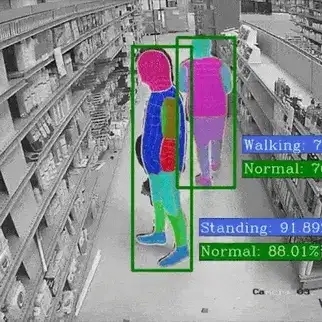
Can you see everything happening here?
- We have the object tracking (the second man is moving from aisle 1 to aisle 2)
- The event detection (at 00:03, a man puts an item in a pocket)
- The action classification (of putting something in a pocket)
- The video decomposition (shoplifting from 00:02 to 00:03 — standing from 00:03 to 00:06)
- The people counting (2 people in the video, one is obstructing the other)
- And more...
Among these, there is the idea of "segmenting" the scene to track the shoplifters through the video. You can see the hands being in red, consistently from frame to frame. So this is the idea of Video Processing, and Video Segmentation is a sub-branch of it focus on the task of segmenting a scene.
There are two types of Video Segmentation tasks:
- Video Object Segmentation (VOS)
- Video Semantic Segmentation (VSS)
Video Object Segmentation
In Video Object Segmentation, we are doing exactly what I did in this video. I define an object to track, send the video to the model, which tracks the object consistently across frames. It's purely "object" based, and is NOT used in a supervised way. For example, you can use semi-supervised video object segmentation, where you define an object on Frame 1, and let the model track it across the next frames... Or you can use totally unsupervised video object segmentation, where you won't even mention the objects to track.
Let me show you an example where I am shoplifting (muahahah):

See? We are able to track my head & hands in blue, and the phone in yellow! That is the idea we're interested in... And even more when we can do this:

Now, to be fair, the floating head experiment may NOT be the most useful thing in this example, but the stolen phone is. Now think of everything we can keep track of cells in health related videos, we can keep track of a player when analysing a football match, and a lot more...
Video Semantic Segmentation
In Video Semantic Segmentation, we'll really go at the pixel level, and rather than focusing on segmenting objects, we focus on the scene. The output is going to look extremely similar to a normal image segmentation task.

Just like image segmentation, you can also use video instance segmentation, video panoptic segmentation, video semantic segmentation, and so on... And of course, there is the benefit of doing background extraction, to then process uniquely what's been segmented, for example in a case like lane detection in self-driving cars:

But from now, you may have a question:
How is Video Segmentation different than Image Segmentation?
I mean, is it really different? It kinda looks similar to. image segmentation, right? And yes, while it may be the case for some examples, like the one I just gave with video semantic segmentation, most of the tasks will be different and give different outputs.
To put it simply: Video Segmentation is about processing videos. You don't process image per image, you process video frames immediately. And this has several advantages:
- The model can track multiple objects even though they're occluded (similar to what object tracking would do, but using video sequences)
- The model can segment specific scenes you're looking for (a blood cell changing sizes, a car entering a scene, a man stealing something)
- It ensures temporal consistency, meaning an object that appears in one frame keeps the same identity/color across the entire video, enabling tracking at the same time.
- It understands object motion, meaning it can predict where an object will be in the next frame instead of treating every frame as an isolated image (thanks mainly to video instance segmentation)
- For some models, it can be more efficient, since instead of running image segmentation on each frame separately, the model processes a video sequence, leveraging temporal information to process frames together, reducing redundant computations.
So, how does that work? What type of model does this? I do NOT have a specific "do this do that" template to share with you, but by studying examples, we could probably understand what's required to make a Video Segmentation algorithm work...
Example 1: VisTR (Video Instance Segmentation Transformer)
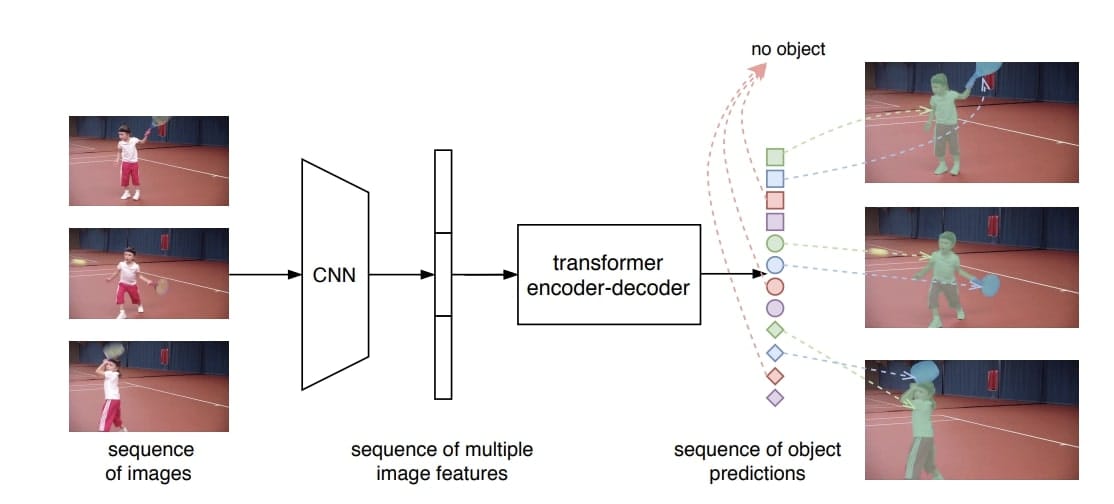
The first paper looks terribly simple. Let's try to understand the different blocks:
- Input: First, we process raw video data, it's purely a sequence of images sent to the CNN
- Backbone: Then a normal 2D CNN processes each frame independently before concatenating the feature maps
- Video Processing: This is fed to a Transformer, known to process sequences quite well. However, we modify this transformer a bit to not just receive a positional encoding, but also a temporal encoding.
- Output: Finally, the output of the decoder predicts instances for each pixel, with a sequence matching strategy
The training is done after obtaining labeled data from the YoutubeVIS dataset, and the backbone is initialized with the weights of DETR.
The detailed version looks like this:
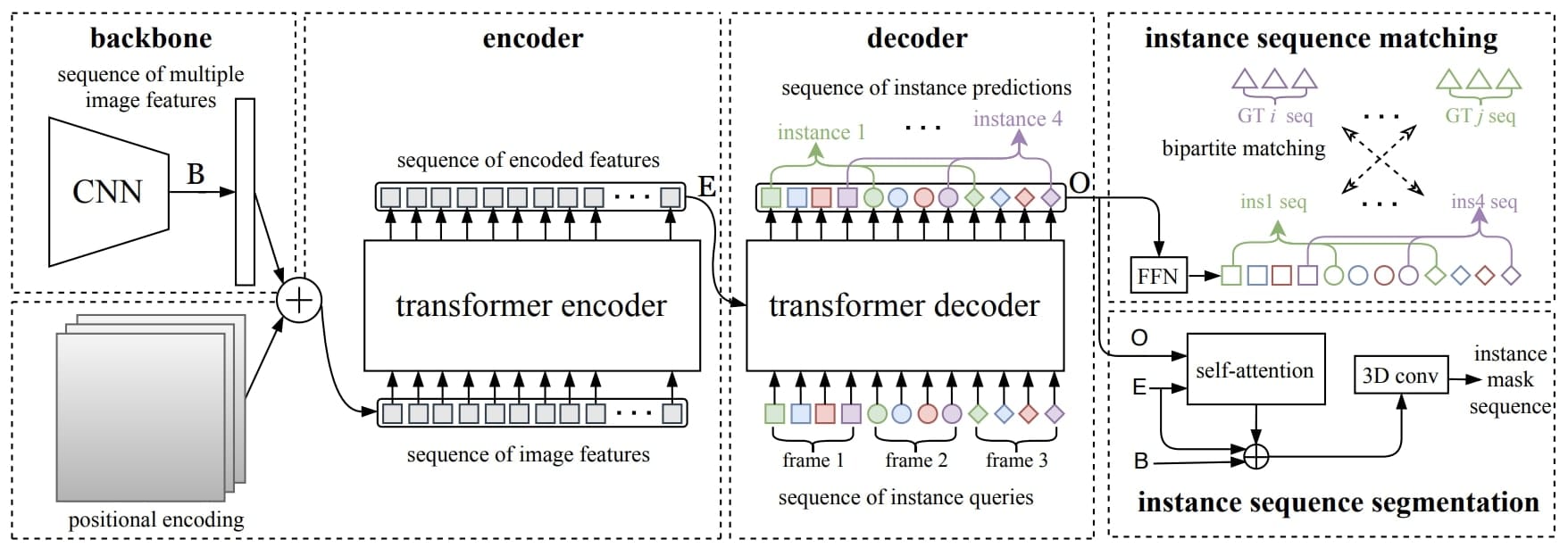
As you can see, we have a video processing pipeline, where the transformer is actually aware of the frames. The segmentation process ends by matching pixels with instances. This is done using Bipartite Matching (the Hungarian Algorithm). More subtle blocks exist, and I invite you to read the paper for more...
Example 2: SAM 2 (Segment Anything 2)
If you didn't live in a cave around 2023, you probably heard of Segment Anything — the segmentation model that could find any object in an image. Recently, it got an upgraded version called SAM2, which is designed to process videos. Let's take a look:
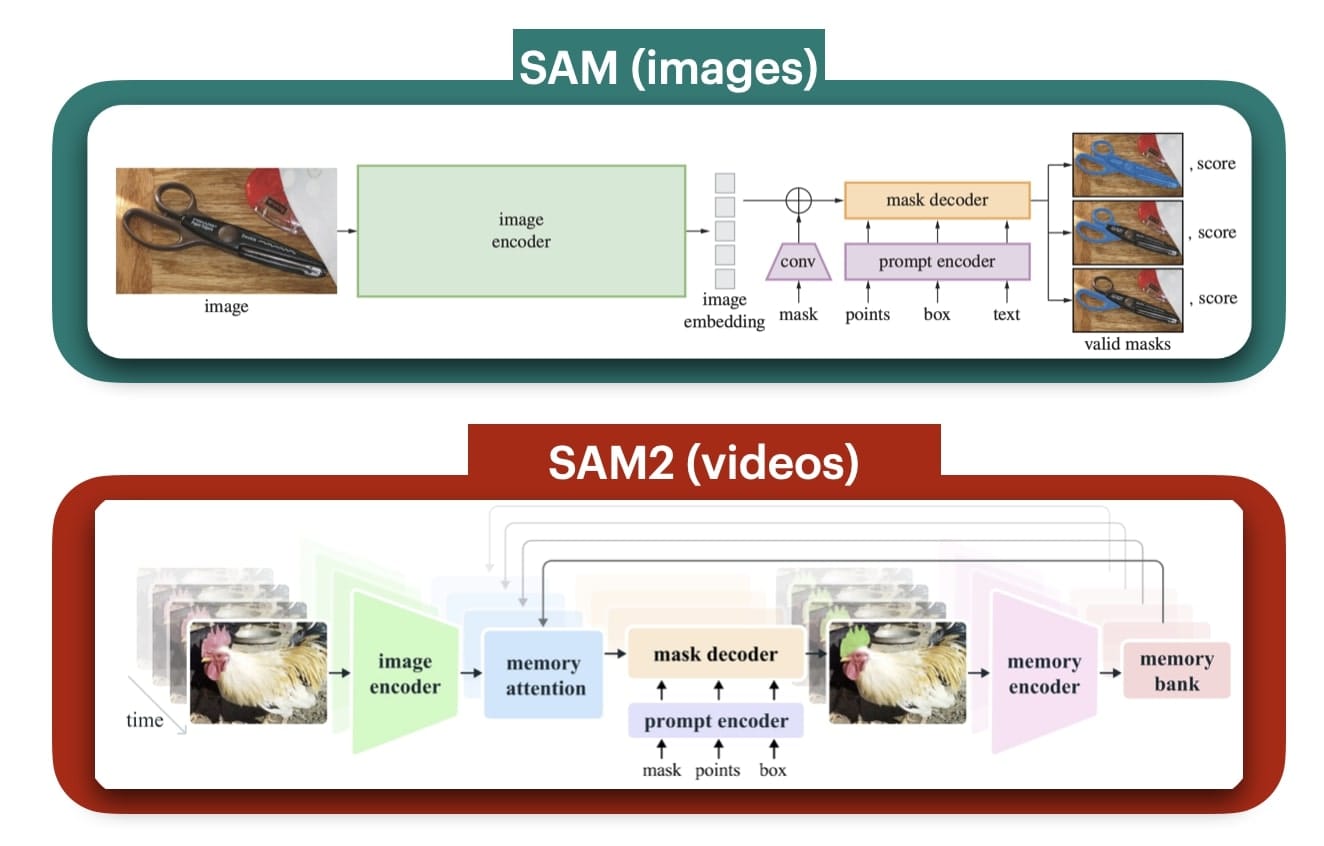
As you can see, SAM 2 differs from SAM by the addition of a memory block, made of a memory attention module, a memory encoder, and a memory bank that stores the past frames, and helps with temporal consistency.
If you played with the online demo, you will find that the model starts by asking you to click on an object, so it can keep tracking it. So at frame 0, you click the object you want to track, and then the model tracks it on the entire sequence...
This is called "Promptable" Visual Segmentation.
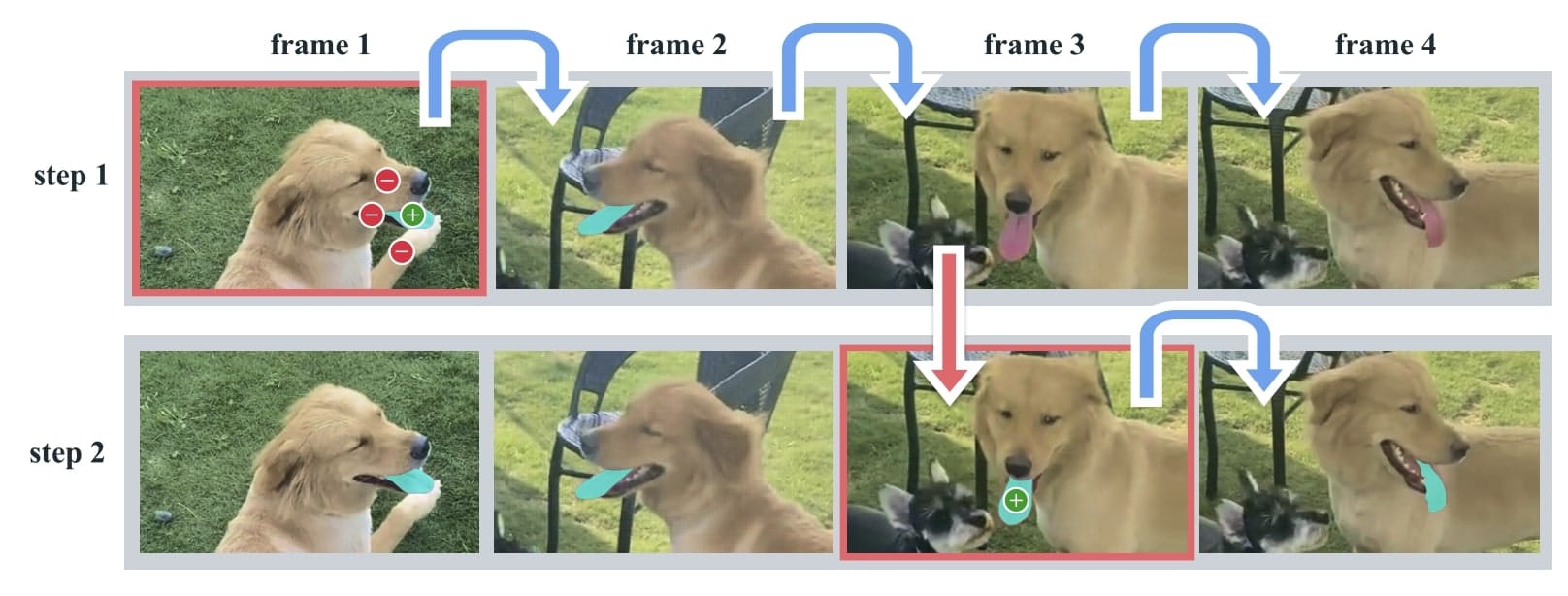
This is no different than the original SAM model, and in fact, it's using the same "prompt encoder". So let's the see the details of the model:
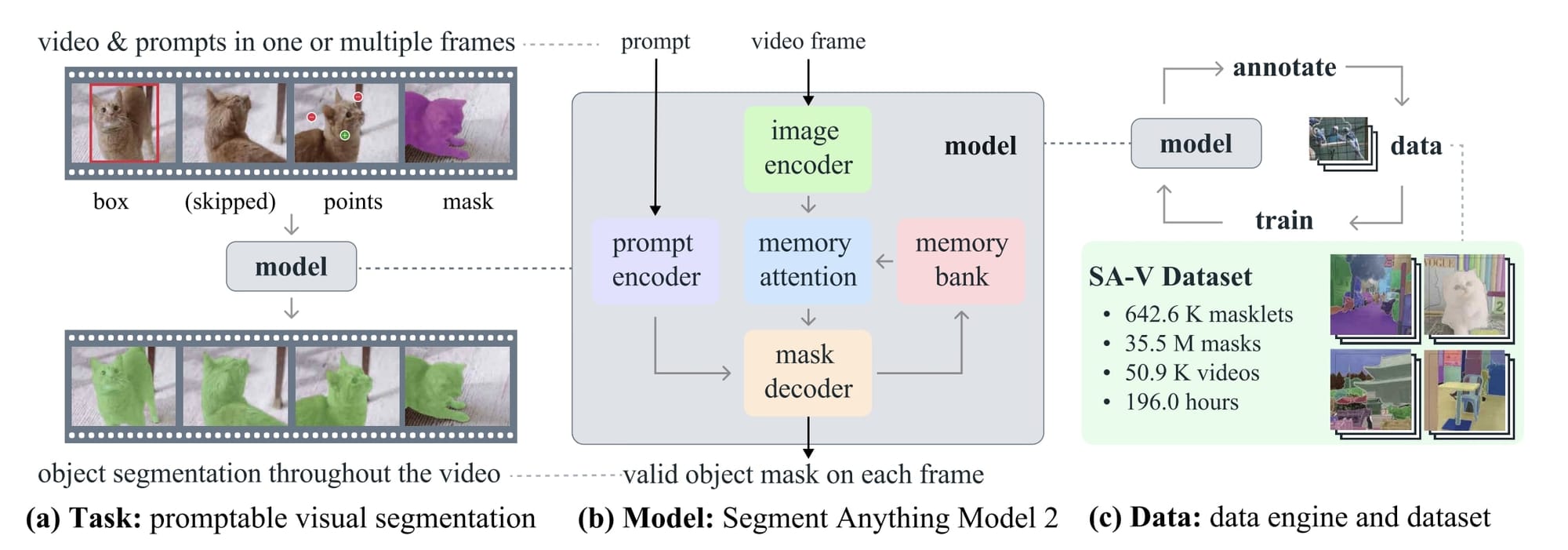
- Prompt Encoder: As expected, we begin by clicking objects, which generates a "prompt", and send this to the same encoder as Segment Anything to track object across each image
- Image Encoder: We then send the entire vide to the image encoder which is a masked autoencoder
- Memory Attention: Uses vanilla attention to condition the current frame features on the past frames features and predictions as well as on any new prompts
- Memory Bank: It retains information about past predictions for the target object in the video by maintaining a FIFO (first in first out) queue of memories of up to N recent frames.
- Mask Decoder (prediction): Similar to SAM, but accounting for previous memory information
So, you saw a second way to build a video segmentation algorithm. The first way was fully transformer based; and this second way has the somewhat robotic "memory bank"; and this because this model is a "hybrid" between 100% video processing, and frame-by-frame processing.
Image vs Video Segmentation: Worth the trouble?
I would say yes, especially considering all the use cases that can benefit video segmentation. For example, surveillance with massive occlusions (in a crowd, with walls, trees, ...) where standard object tracking would be limited, video editing, where for example, we want to remove an object not from one frame, but from an entire scene, sports analytics, entirely based on motion, cell tracking (for example, division of cells, which can only be seen via videos), shoplifting detection (which can't really be seen in an image), fire spreading, and more...

You can see this article for the normal image segmentation use cases, and I highly recommend you augment it in your mind with these video examples I provided. So as a rule:
- For most cases, don't replace all your image segmentation pipelines with video pipelines
- But for the cases where segmentation fails because you need to understand video, do it!
Alright, we've seen a lot, let's do a summary...
Summary & Next Steps
Congratulations on getting so far! Let's summarize what we learned:
- In many cases, analyzing one event fails. When video is essential, you have to use Video Computer Vision models.
- Video segmentation is segmentation applied to video processing, it's used in in various fields like surveillance, retail, sports analysis, shoplifting detection (or detecting suspicious behavior of any kind) and healthcare.
- Video Segmentation splits into two categories: Video Object Segmentation and Video Semantic Segmentation.
- Video Object Segmentation (VOS) focuses on tracking defined objects across video frames. Many applications like SAM2 are semi-supervised, because you give the model a prompt and an initial object to track.
- Video Semantic Segmentation focuses on pixel-level scene segmentation, it can also be instance or panoptic based, and the output may resemble the one of standard image segmentation.
- Some models like VisTR can be 100% video processing based. This model uses transformers for video instance segmentation.
- Other models can process frames one by one, but rely on a memory bank. In the case of SAM2, frames are processes both as a video and one by one (to keep track of a same object)
Next Steps
A few articles you can read:
- Introduction to Video Processing — an old post (you can see my writing style is much different) but good overview on Video Processing.
- A complete overview of Object Tracking Algorithms in Computer Vision & Self-Driving Cars - very related to video object processing, but without the segmentation part (bounding boxes).
It's all in my App, along with 5+ hours of advanced Computer Vision content — available when you join my daily emails. Here is where you can learn more.