Faster RCNN in 2025: How it works and why it's still the benchmark for Object Detection
A day in 2018, I was buying my first car, an Audi A1, when the sales representative pitched me about the "sportback" version; which was supposedly more powerful. "Why?" I asked. And it turns out, it had more horsepower than the classic version. Horsepower? The idea intrigued me, especially since it's been a century since people replaced horses with cars, and yet, we still use horsepower as the key metric to describe a car.
This metric, while seeming outdated, is still used as the gold standard in automotive... and it reminds me very much of the Faster-RCNN algorithm in object detection.
The Faster RCNN algorithm got introduced to the AI community in 2015, and even though it's been 10+ years now, you still see it listed as the benchmark in most new object detection papers. Somehow, Faster RCNN is still the reference researchers use when they create a new algorithm.
Take, for example, the paper CO-DETR, which is doing Object Detection with Hybrid Transformers, something super-advanced, released late 2023 (almost 10 years after Faster RCNN), and notice the papers it's being compared to: Faster RCNN is part of the list.
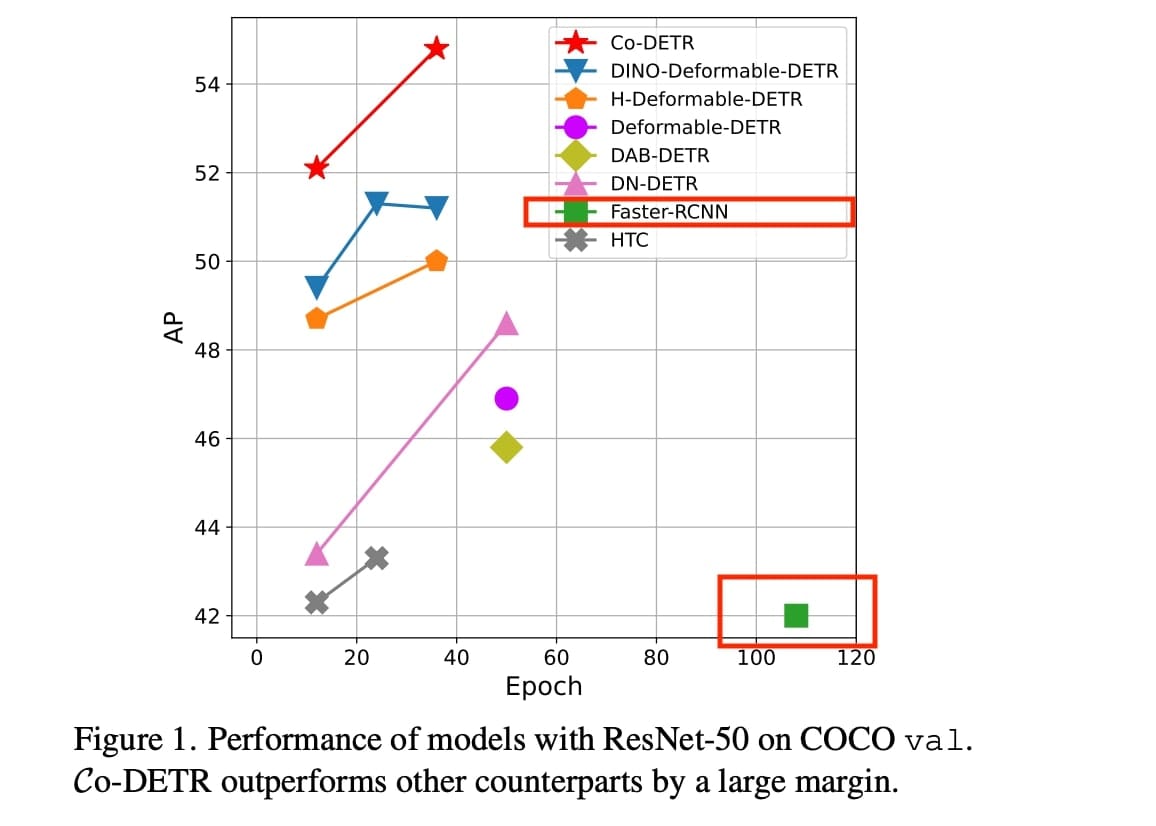
Have you noticed? And it's the case for almost every paper!
Why? Back when the algorithm got first released, and somewhere around 2018, I was looking for an object detection model to integrate in my autonomous shuttle, and it seemed that the entire market came to 3 conclusions:
- SSD (Single Shot Detector) is the fastest object detection network
- Faster R-CNN is the best model for accuracy, especially with small objects
- YOLO (You Only Look Once) is the best tradeoff between accuracy and speed
Yet, the original YOLOv3 got replaced several times, and the Faster R CNN model still continued to live. In this article, I'd like to describe the model to you, explain its key components, and help you understand whether you should spend time on it or not.
Before we dive into this algorithm, a quick aside:
When I first learned about object detection, it was through the Udacity Self-Driving Car Nanodegree where we learned a Machine Learning technique called 'HOG+SVM', which worked like this:

The image was sent to an algorithm that ran a sliding window, and for each window, extracted Histogram of Oriented Gradient features that it classified using a Support Vector Machine (SVM). It was old, fully "traditional", but somehow worked. I doesn't win an object detection oscar, but it did work. The idea was what we call a two-stage object detector:
- We propose regions or bounding boxes (in this case, we defined window dimensions)
- We classify each region
And here was the output:
The Faster-RCNN algorithm is built exactly on the same "Two Stage" principle, except that it replaces every single one of these techniques by Neural Networks.
Let's see how:
R-CNN: Selective Search
The first idea was to replace Feature Extraction, which was done using Histogram of Oriented Gradients, with a CNN (Convolutional Neural Network). Here it how it worked:

The algorithm had a few steps:
- Propose 2,000+ Regions using Selective Search Algorithm
- For each region, extract features with a CNN (Convolutional Neural Network)
- For each region, classify the features using SVM (Support Vector Machine).
The idea was almost similar to my project, except that the region proposal network was done using Selective Search, an old Computer Vision algorithm, and the extraction was done using CNNs.

The algorithm had several problems: too many useless regions, too much extraction to do, and every region had to be resized/rewarped manually to match the CNN input layer.
This wasn't ideal...
SPP-Net: Adding a Spatial Pyramid Pooling (SPP) block
SPP-Net is an evolution of this paper using a clever technique called Spatial Pyramid Pooling. The idea was as follows:
- Extract the Features using a CNN first
- Propose 2,000+ feature map Regions using Selective Search.
- Use Spatial Pyramid Pooling to avoid cropping/warping regions
- Send each feature map to FC layers and classify using SVM
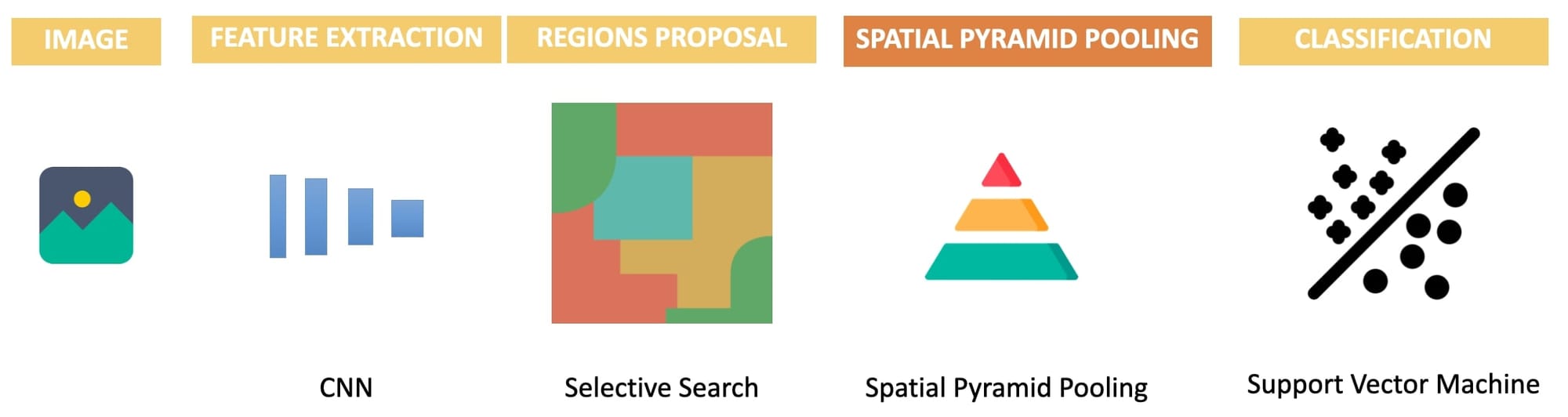
And the idea worked! Working on the features instead of the regions helped remove some noise, and introducing Spatial Pyramid Pooling helped look at the image from different aspect ratios using multiple 'Max Pooling' operations.
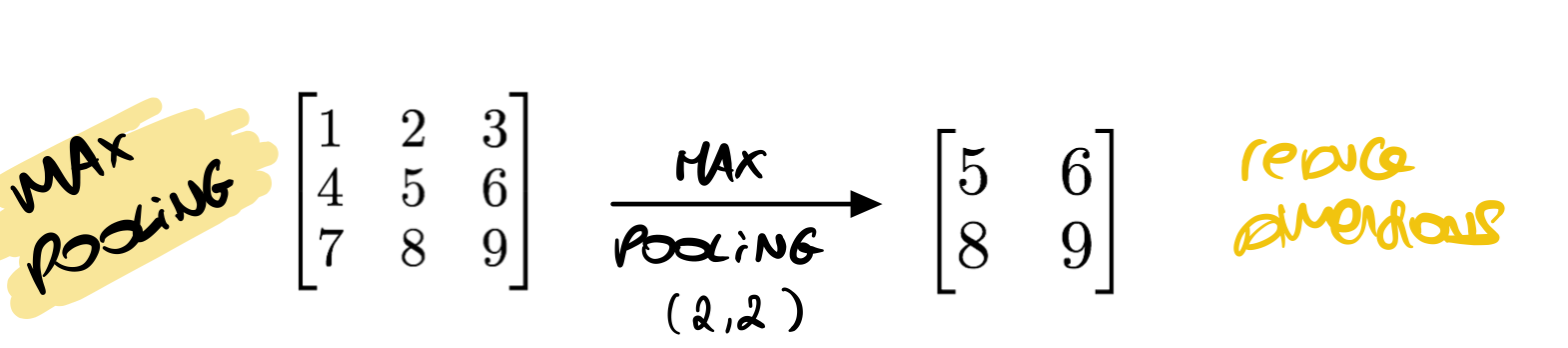
Let me briefly take you back to the Max Pooling idea: it takes a window (say 2x2) and computes the maximum to reduce the size of the input, so that a 500x500 images becomes 250x250.
Spatial Pyramid Pooling is doing a similar thing, but at multiple different scales, like (1x1), (2x2), (3x3), etc:
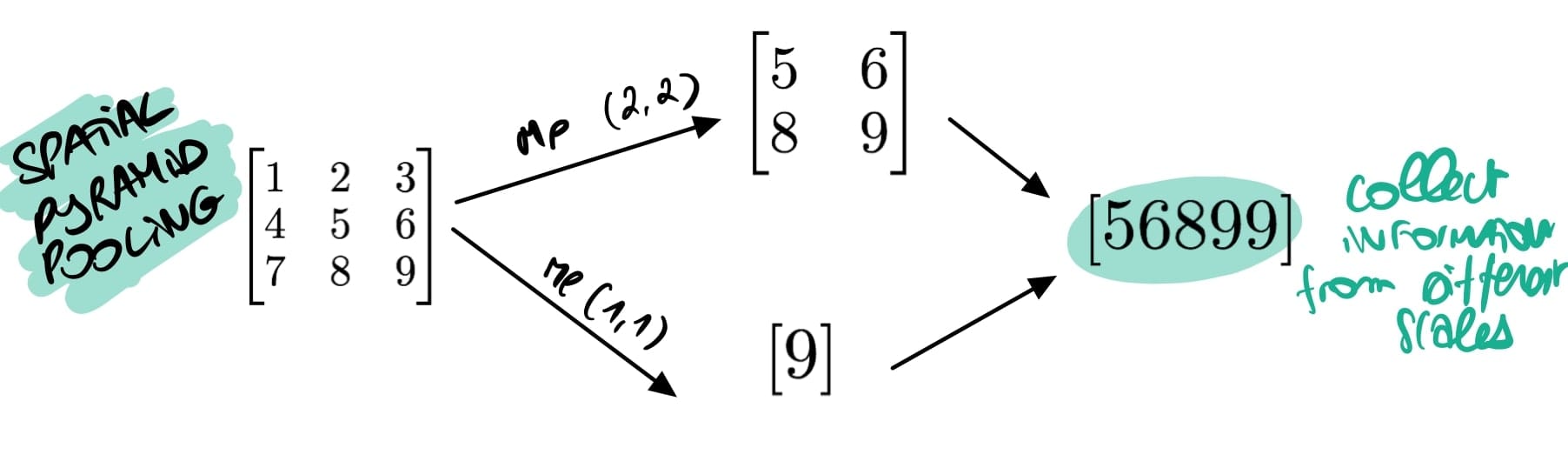
The idea: collect information from different scales.
So far, we replaced the Feature Extraction with a CNN, and we added an SPP. What now?
Fast R-CNN: Adding Neural Network Classification & ROI Pooling
Comes the Fast R-CNN detector! And the idea is almost the same, except that it replaces the Spatial Pyramid Pooling with ROI-Pooling; and the final SVM with a Multi-Layer Perception classifier:
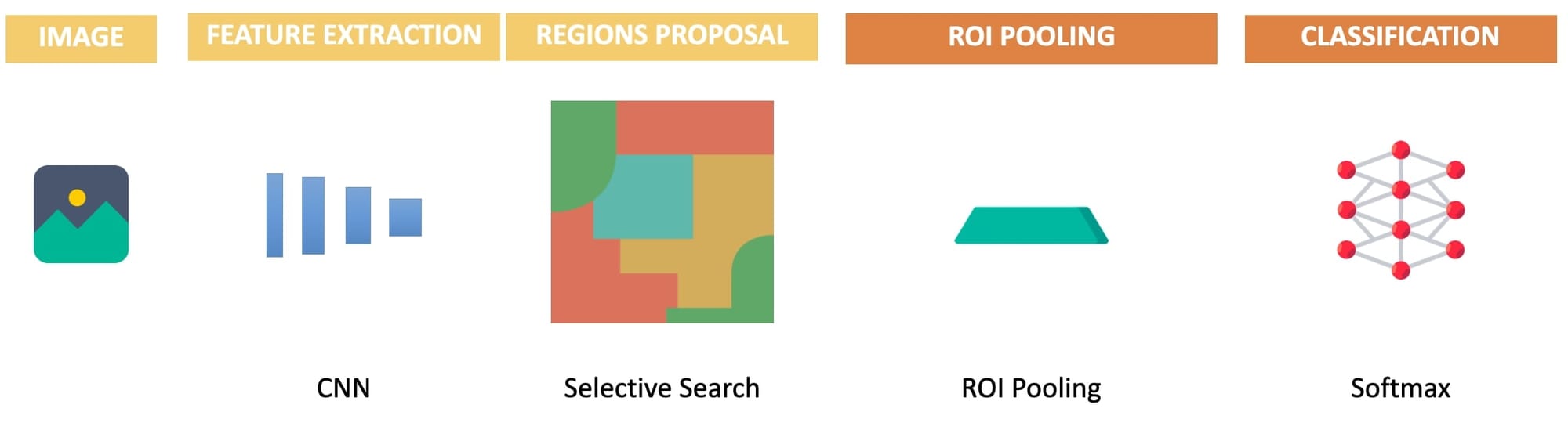
Notice the key steps:
- Extract the Features using a CNN
- Propose 2,000+ Regions using Selective Search.
- Use ROI Pooling to avoid cropping/warping regions
- Send this to FC layers and classify using a neural network
There are two ideas of the Fast R-CNN architecture: ROI Pooling & FC Classification.
1. ROI Pooling: SPP in better
ROI Pooling is a special case of Spatial Pyramid Pooling, with an added idea of focusing on a specific region.
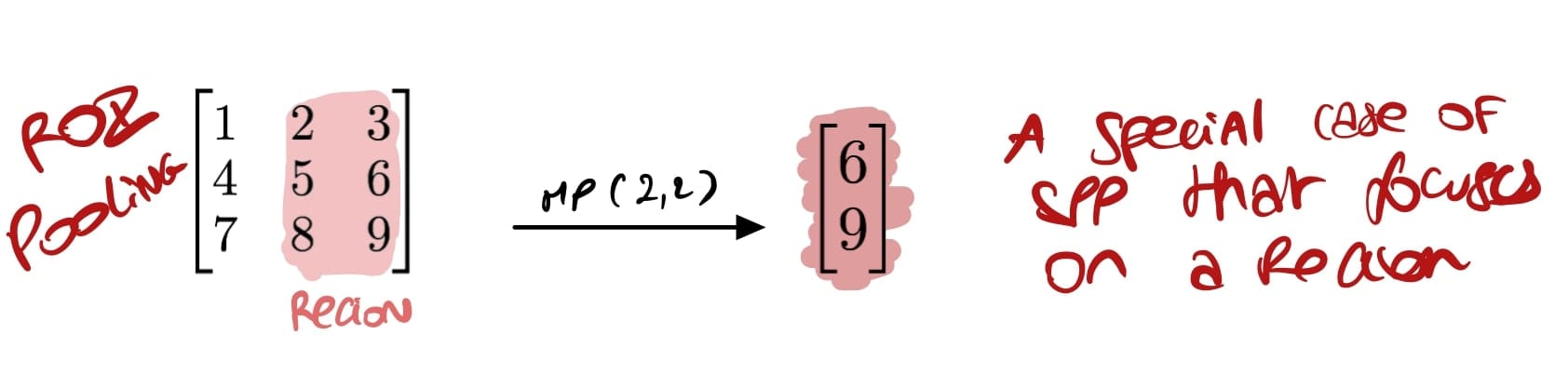
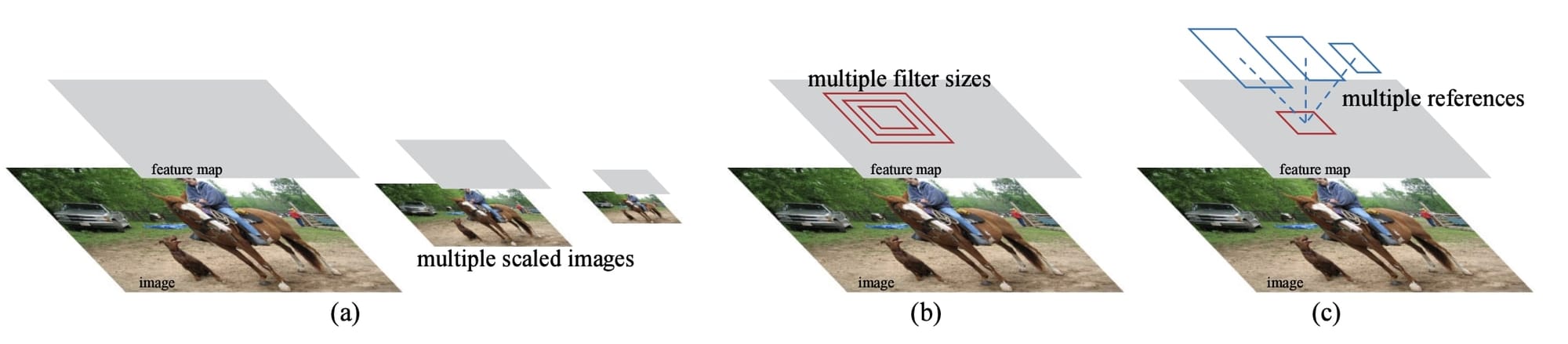
This is particularly useful in two-stage object detection algorithms that first propose regions using algorithms such as Selective Search or as in Faster RCNN, Region Proposal Networks. This last technique is also super fast compared to SPP that computes pooling several times at different scales (it also computes pooling for all regions directly).
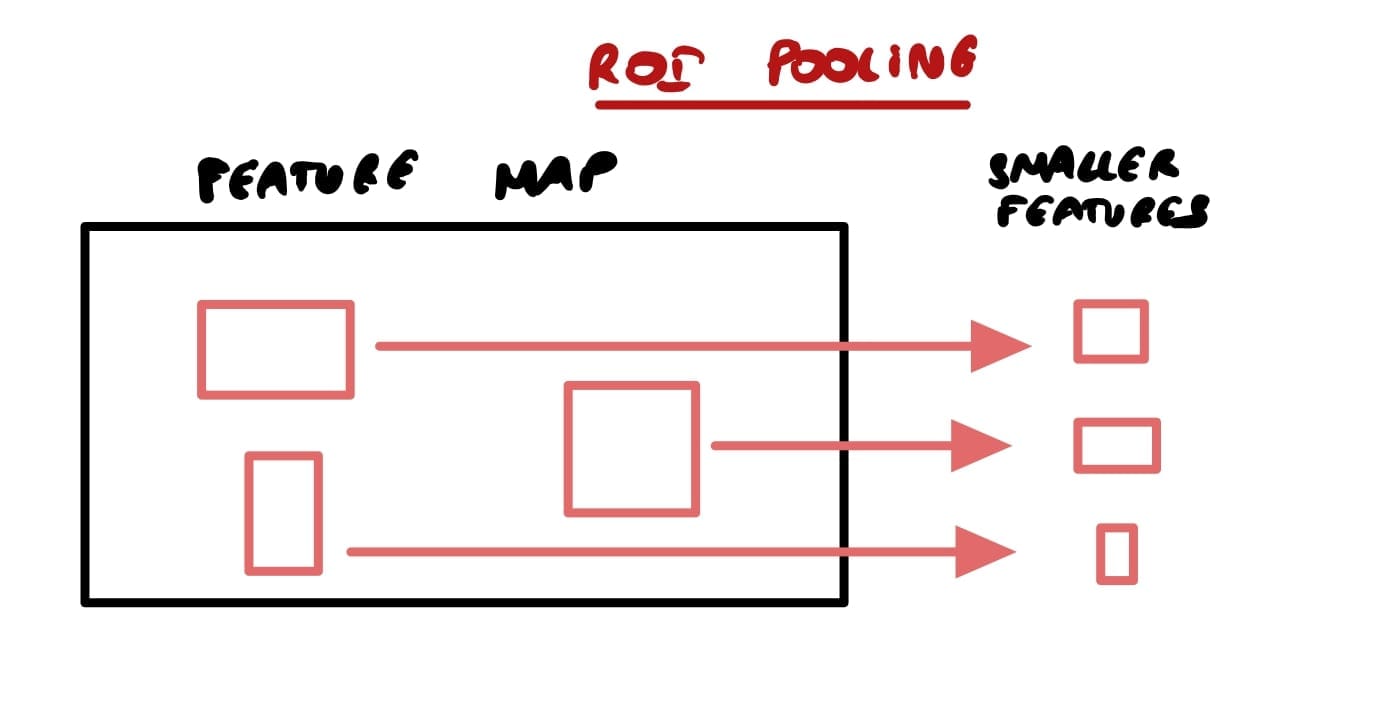
One thing that you can notice about this technique is that by working on different scales, it allows the network to be more accurate, especially with different sizes of objects. Many objects detection models use anchor box techniques to find bounding boxes. The problem is, you must manually define the anchor boxes every time. In this process, we find the regions first (rather than some boxes), and then extract information about these regions.
We can see this on the Faster-RCNN paper (which uses this same technique) as well:
2. Fully Connected Classifier: SVM in better
The second addition is to replace the traditional Machine Learning SVM (Support Vector Machine) with a Softmax layer. There isn't much to comment here — we're using softmax on the k region proposals to do object classification for each bounding box. And this is an idea used in Fast R-CNN, but also in Faster-R-CNN.
Speaking of it, there is one last evolution to go from Fast R-CNN to Faster R-CNN:
Faster R-CNN: Replacing Selective Search with a Region Proposal Network (RPN)
When we started the algorithm in 2013, we had almost everything done by traditional techniques:
- We proposed regions using Selective Search (old school computer vision/segmentation)
- We did feature extraction with CNNs (this was Deep Learning)
- We classified the features using SVM (traditional machine learning classification)
And progressively, we replaced SVM with a Fully-Connected Layer, and we improved the CNN extraction with pyramids. What is left to replace with Deep Learning? The Selective Search algorithm! And yes, it was really an old and slow Computer Vision technique:
Faster R-CNN replaces selective search with a Deep Learning based Region proposal Network (RPN). This way, everything is trained end to end using a unified network. It's all a single network!
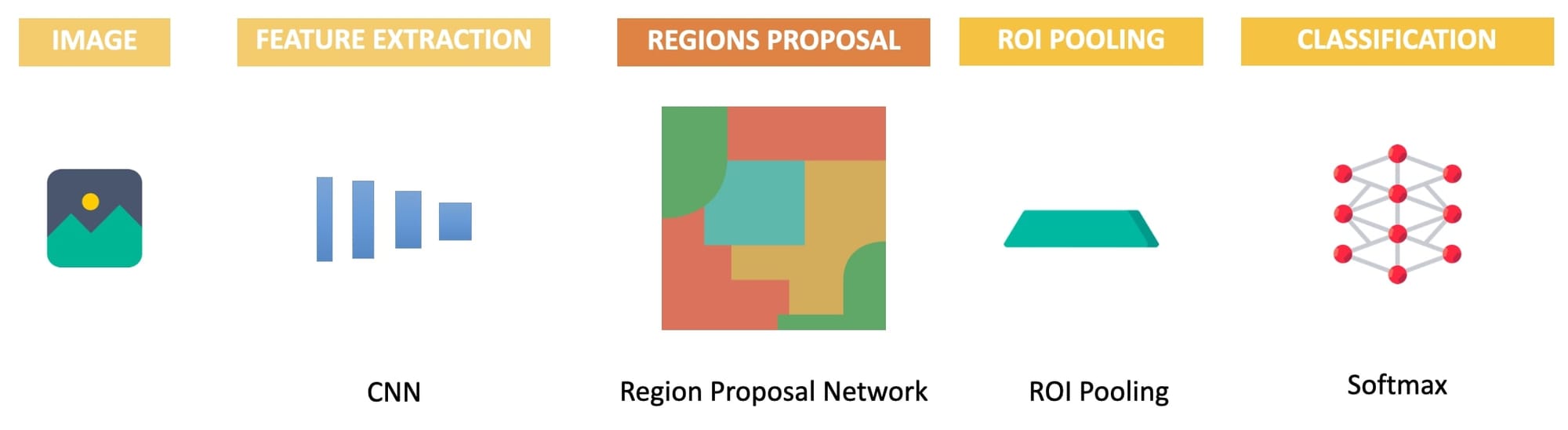
The full process goes like this:
- Extract the Features using a CNN
- Generate Region Proposals using a Region Proposal Network.
- Use ROI Pooling to avoid cropping/warping regions
- Send this to FC layers and classify using a neural network
And here we are!
Now what is this RPN doing? It serves as the "attention" of the network. It's designed to generate high quality region proposals and highlight where there might be objects. Taking an image of any size as input, it uses a fully convolutional network to output a set of rectangular bounding boxes, each with an objectness score. When you think about it, the name of the paper Faster-RCNN is "Towards Real-Tme Object detection with Region Proposal Networks".
How is a Region Proposal Network making it any real time? By removing the selective search algorithm and working on the feature maps directly, it kills the need for heavy computations, and does cost free region proposals. The RPN operates on the same convolutional feature maps produced by the backbone CNN (e.g., ResNet or VGG) that are already computed for object detection.
It then uses the concept of 'anchor boxes' to do the region proposal generation. If you're not familiar with the concept of anchor boxes, the idea is to define boxes of multiple aspects and sizes, and try to have objects fit these boxes. For example, a vertical small anchor box is a pedestrian seen by far — a vertical big anchor box is a pedestrian close to the camera.
I highly recommend my article "Finally Understand Anchor Boxes in Object Detection" to grasp the idea.
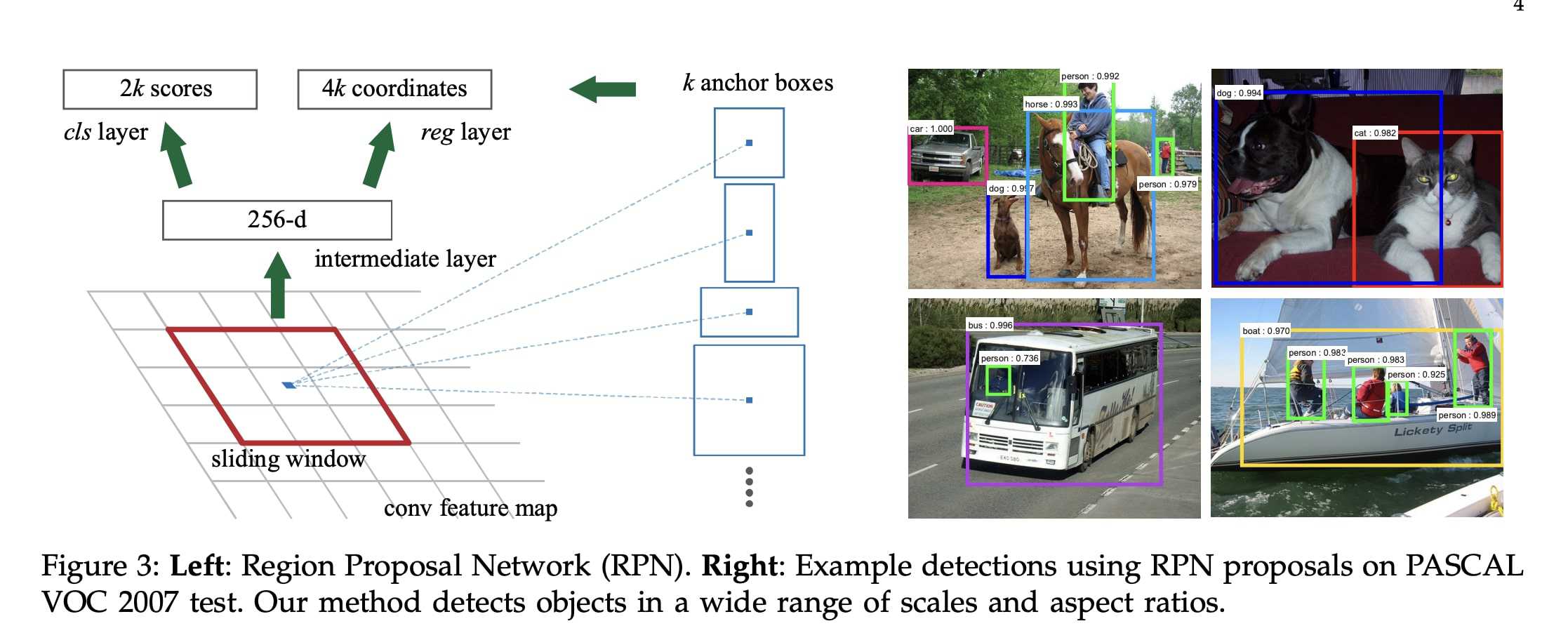
Using the FCN in Fast R-CNN and this new RPN, the algorithm can simultaneously predicts object bounds and class probabilities.
And we have it! The paper Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks is really performant, because it uses all of these ideas. Being a 2-stage algorithm, it's powerful and can find small objects as well as big objects. It's a bit slow, but the enhancements made to the region proposal network are much better
Let's now see an example:
Is Faster-RCNN still used? Where would it fit best?
I don't think people today would use Faster R-CNN as the main choice for their algorithm. There are many powerful, better, and faster object detectors. Yet, if there was one place where I'd use it, it'd be on the task of Traffic Light Detection & Classification.
You see this all the time; traffic lights have a separate network designed just for them. These networks are usually focused on finding smaller objects, detecting the states, and using the long-range camera focused on lights.
Here, you will find Faster-RCNN possibly used. Probably more than anywhere else, because this algorithm is accurate and working well with small objects.
Should I try to recode it on my own?
If you have never implemented object detection, I would recommend to first go to the HOG+SVM traditional techniques. Then, you could try to run Faster R-CNN first, and then maybe implement some bricks. Today, YOLO is more dominant, and understanding this algorithm would make a lot of sense too.
What's to understand is that the real going behind object detection is not necessarily to find objects, but rather to extend it to things like LiDAR/Camera Fusion or object tracking. This is where the real value of object detectors is.
Summary & Next Steps
You've been through the article! Congratulations! Let's do a quick summary of everything we learned. First, you probably now understand this image:
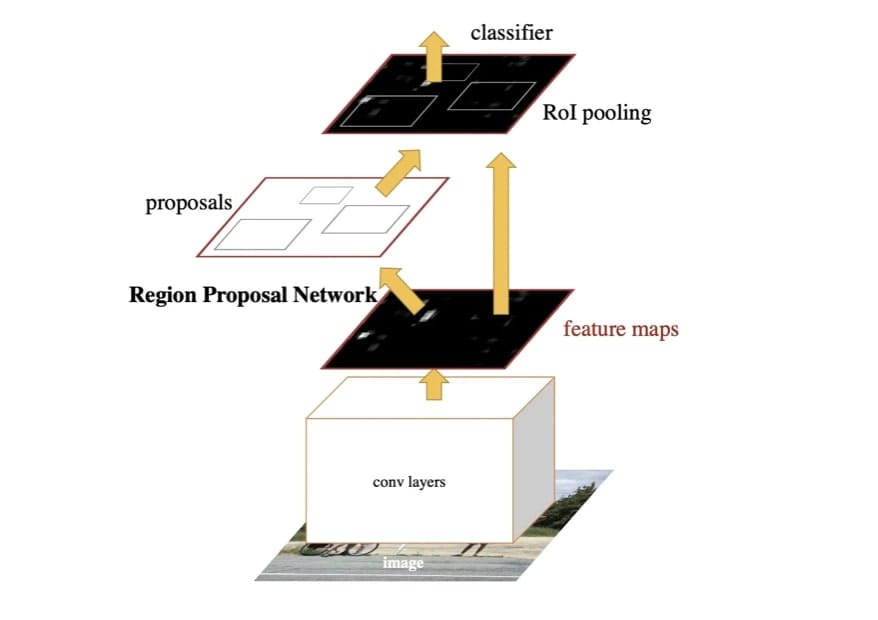
Here is what it was about:
- Faster R-CNN remains a benchmark for object detection, even a decade after its introduction. The algorithm is known for its accuracy, especially with small objects, and is often compared to newer models like YOLO and SSD.
- Faster R-CNN evolved from traditional techniques, replacing each of them with neural networks; from region proposals, to feature extraction and classification.
- HOG feature extraction was replaced with CNNs in Fast-RCN, allowing to build feature maps.
- Spatial Pyramid Pooling, and later ROI Pooling and anchor boxes got added for better extraction, proposal, and understanding.
- Region Proposal Networks (RPN) replaced Selective Search, allowing the model to generate high-quality region proposals in real-time.
- A fully-connected layer replaced SVM for classification.
- Despite being slower than some modern detectors, Faster R-CNN excels in tasks requiring high accuracy, such as traffic light detection.
- The model's two-stage process involves proposing regions and classifying them, making it powerful for detecting objects of various sizes.
Next Steps
Here are a few articles I'd recommend you learn next to continue your journey:
- Finally Understand Anchor Boxes in Object Detection (2D and 3D)
- Computer Vision for Multi-Object Tracking: Live Example
- Instance Segmentation: How adding Masks improves Object Detection
And of course, the most important recommendation of all:
Subscribe here and join 10,000+ Engineers!